
Since the early days our professional services team has been actively assisting customers with data migrations. I still have nightmares about these times, crammed in a tiny office in downtown Royal Oak, burning the candle at both ends, with extremely aggressive deadlines, conflicting and complex business requirements, and high energy / high temper customer teams. We have invested a lot of energy supporting our customer as it went through a period of aggressive growth through buying hundreds of regional companies over a short period of time. Mergers and Acquisitions are never easy, especially when acquired companies must adapt to the new mothership’s processes and platforms. Data migrations are a key step in the process. When done right, they reduce the frictions and increase the chances of success, and when not… well it’s no secret that 70% to 90% of acquisitions fail. Our customer grew to become a market leader, and we ended up with a battle tested team and a playbook for complex data migrations… and an occasional nightmare
Last year our MuleSoft services team was tasked with data migration for a leading SaaS security provider being merged into a global technology organization. Both companies leveraged heavily customized Salesforce orgs to support their GTM processes. Business and functional teams spent months (or years) formulating the high-level strategy, detailing to-be workflows and object and field mapping between the two orgs. Once that is completed, the technical task of migrating the data from one Salesforce org to another should be a walk in the park, right? That was our hope, but as always, the devil is in the detail!
As we started researching the available tools, we quickly realized there was nothing out there to support our requirements out of the box. There were several constrains and considerations for this process:
- Both source and target Salesforce orgs were highly customized, with many additional objects, fields, and automation requiring complex transformation rules. In some cases, multiple target records in various objects had to be created based on a single source object record, and vice versa.
- Both source and target orgs had operated on large data volumes, with 500k+ customers and millions of contacts, subscriptions, leads, opportunities, and other key data objects.
- The data migration process must support full sync and incremental updates and could be executed on a schedule to surface the data in the target system while some teams still work with the source system.
- Every data migration run must produce verifiable data quality / balancing / certification reports to ensure there is no data loss and prove every single eligible entry from the source system has made it to the target system. If the record was rejected it should be easy to find out why (for example due to internal validation rules or failed automation in the target system)
- Complex object hierarchies must be retained after the data is migrated, including parent / child references within the same object (for example one Account record could reference to a parent Account record), as well as across the objects (for example multiple Opportunity Line Items could be linked to Opportunity Header which in turn is linked to Account which refers to User and other objects).
- Some business entities already existed in both systems and the data had to be merged rather than duplicated. The deduplication / search before creating the check would have to be done in a way to support single-pass one-way bulk data load and avoid the read-search-write record level approach as it would take weeks or months to complete due to the large data volumes.
Our team has already been running quite a few integrations based on MuleSoft – a highly efficient enterprise-grade API and integration platform. After considering several alternatives we decided to use MuleSoft for this data migration process and reuse the security, quality of service, alerting and monitoring, and other features that come out of the box with the platform and the extensions our team developed over the course of the years. The complex transformation and deduplication requirements ruled out the “drag and drop” one-to-one basic data export / import tools, and MuleSoft’s low code integration development environment coupled with Dataweave (powerful and descriptive data manipulation language) seemed like the right tool.
Below is a high-level solution design: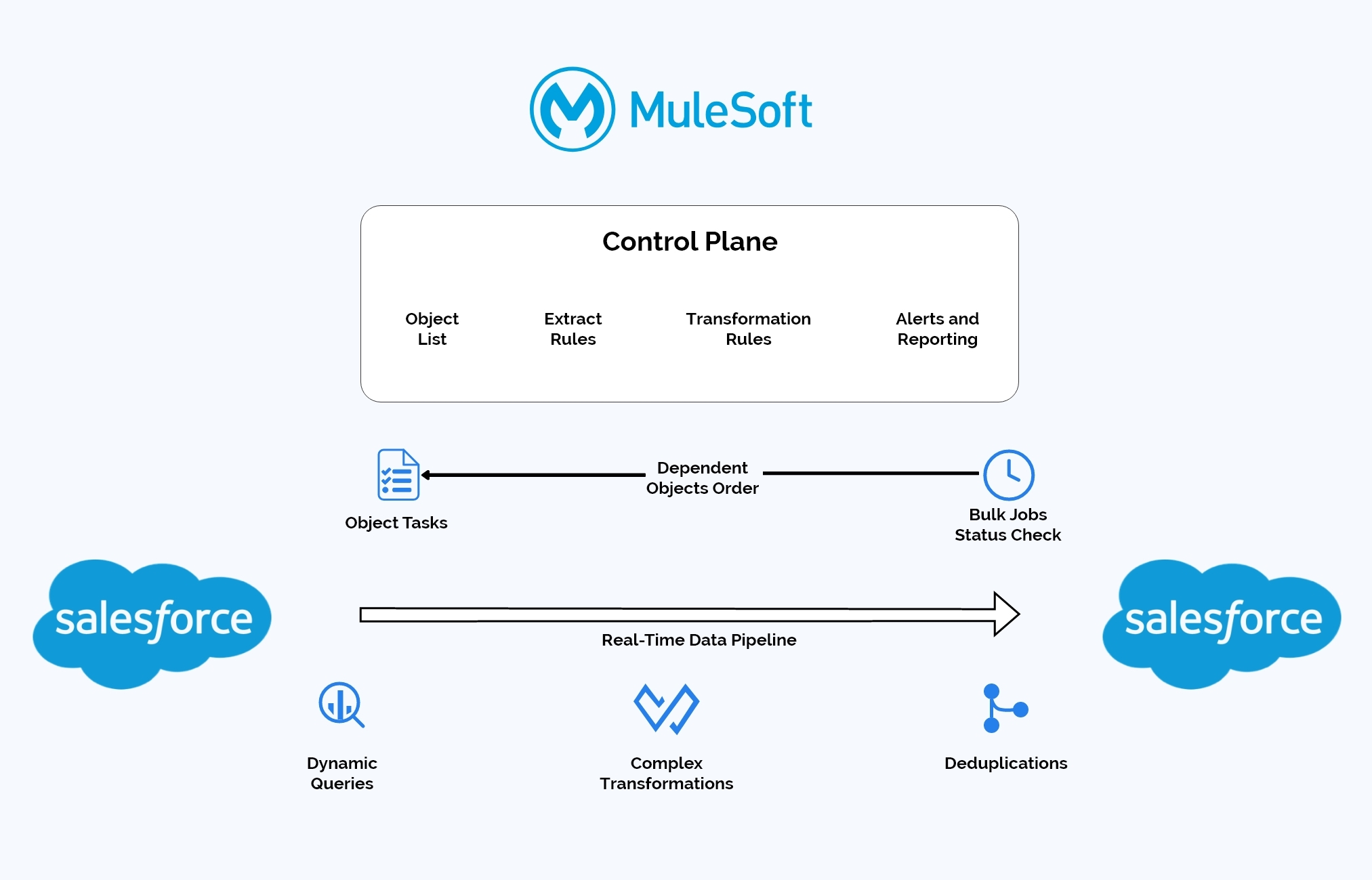
The final product had the following features:
- We aimed to process the data in real time parallel streams without any intermediate data staging
- We leveraged Salesforce Bulk V2 APIs that support very large data volumes. Due to the async nature of Salesforce batch processing we implemented a status check process to ensure dependent objects will only be processed after the parent objects’ bulk job has been finished.
- We decided to externalize the configuration for the objects in scope, processing order, selection rules, transformations (as MuleSoft Dataweaves), and deduplication, as well as leverage multiple utilities and services that have already been implemented as part of the platform, to capture the balancing metrics and implement alerting and exception reporting.
- We had to add several specialized columns to all target objects in the scope:
- External ID to store Source object IDs
- External Reference IDs that would be used to point to parent records during bulk upserts without a need to retrieve the parent ID values first from the target system
- Deduplication IDs – composite fields that are pre-populated with the concatenated values of all key fields in the target object and used as a key for the bulk upserts
- Clean-up and deduplicate the data in both source and target systems prior to executing the first bulk process
It took us some time to implement the overall wiring of the flow but once it was done, adding new objects to the scope, or changing the rules, was just a matter of tweaking the configuration data, with little to no application changes required. In the end, we managed to deliver a dynamic, scalable, and efficient data pipeline that could be quickly configured to include all or a subset of Salesforce objects, with default or custom selection, transformation, referential integrity, and deduplication rules. The tool was reasonably responsive, considering the asynchronous nature of Salesforce bulk processing, without any intermediate staging and no repeated roundtrips.
Data migrations are never easy when both source and target systems are based on the Salesforce platform even with slightly different data models. There is no product that automatically detects and supports the referential integrity and right order of object processing. MuleSoft platform is a powerful low code integration environment and a highly efficient data pipeline that accelerated delivery and took care of the low-level wiring and quality of service aspects. Last but not least, our services team developed a vision, architected the right solution, and turned it into a practical design and successful implementation, all in a reasonable amount of time.
Recent Comments