
This article is a continuation of the IBM i integration series and builds on near real-time bi-directional Order flow between IBM i and Salesforce we walked through a few months ago. As a reminder, it was fairly straightforward to send the Salesforce order to IBM i “ERP” with the Mulesoft Anypoint platform and our infoConnect connector, wrapping a business logic (Order Import program) into a reusable, secure, and standards-based API. The implementation required little to no IBM i specialized knowledge and any Mulesoft developer could use the connector to define the back-end program name, location, and parameters. Easy!
However, the order status update from IBM i back to Salesforce did require us to roll our sleeves and develop a back-end program that streams the order status changes to Mulesoft via IBM i Data Queues. Shouldn’t be a problem for companies blessed with capable IBM i development teams that have some spare time, and a modular and easy-to-modify back-end application. For many customers, however, the IBM i teams are stretched thin, and the back-end applications might be very complex. Wouldn’t it be nice to capture IBM i database changes in near real-time and stream them back to Mulesoft without writing a single line of RPG or Cobol code?
As you’ve already guessed by now, the story build-up is inevitably culminating in a sales pitch. Those are the rules of the game my friends, so here it goes. The primary motivation behind infoCDC – our upcoming lightweight IBM i Change Data Capture (CDC) product – is to provide a configuration-only, no-code-required option for sensing and streaming the IBM i database changes to external applications. When it comes to our Salesforce example, we will “retire” the custom IBM i integration program we built for the initial example, and replace it with infoCDC. The end result is the same – the order status change is detected in near real-time and sent to Mulesoft via Data Queue. There will not be any impact on the Mulesoft DQ listener or the upstream integration components.
The tool consists of the configuration UI and the Change Data Capture listener. Currently, infoCDC leverages IBM i journals to continuously listen for relevant changes and stream them via IBM i Data Queues to integration or messaging platforms such as Confluent Kafka or Mulesoft.
infoCDC Configuration
First, we need to define our Orders table in the infoCDC admin UI:
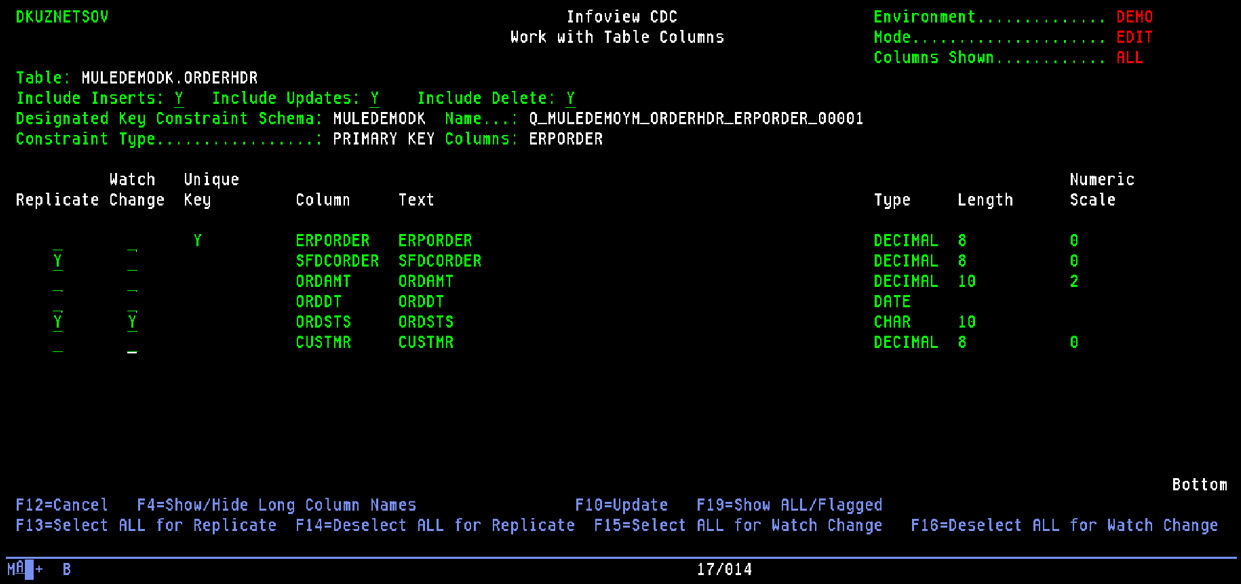
The application automatically detects the table’s primary key, the columns, and data types, and checks if the table is attached to a journal.
For our sample use case, we are only interested in order status updates and don’t care much about record inserts or deletes, or when any other order fields are changed. We check the Order Status column to watch for a change and specify just a subset of the columns we want to replicate (the Salesforce order ID and the status). This ability to filter out irrelevant changes before they are even sent to the target systems can greatly reduce the amount of data being pumped through the pipes, especially for legacy applications that tended to have denormalized tables with hundreds or sometimes thousands of columns!
As we save the table configuration, the tool will auto-create all necessary replication objects (Data Queue, CDC Replication Flow definition, etc). We can check the details on the infoCDC Replication Flow screen:
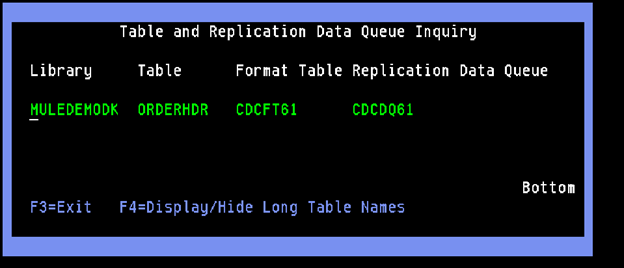
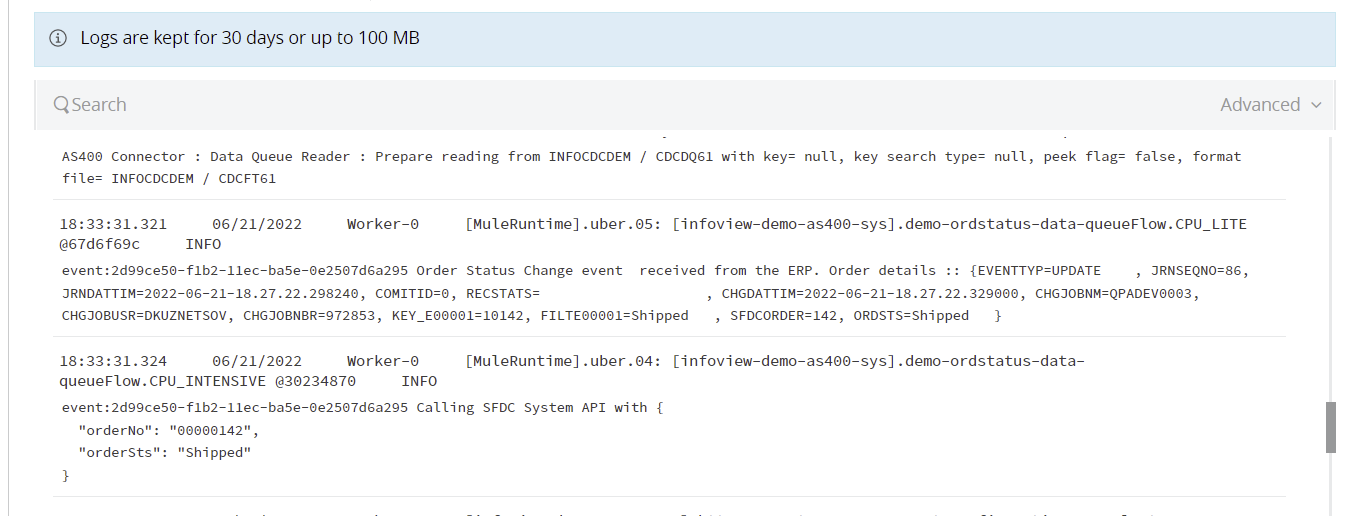
Now we are all set to configure our Mulesoft or Kafka connectors to continuously listen for new Data Queue messages and process them as necessary. In this case, we PUT the status changes to our Salesforce System API.
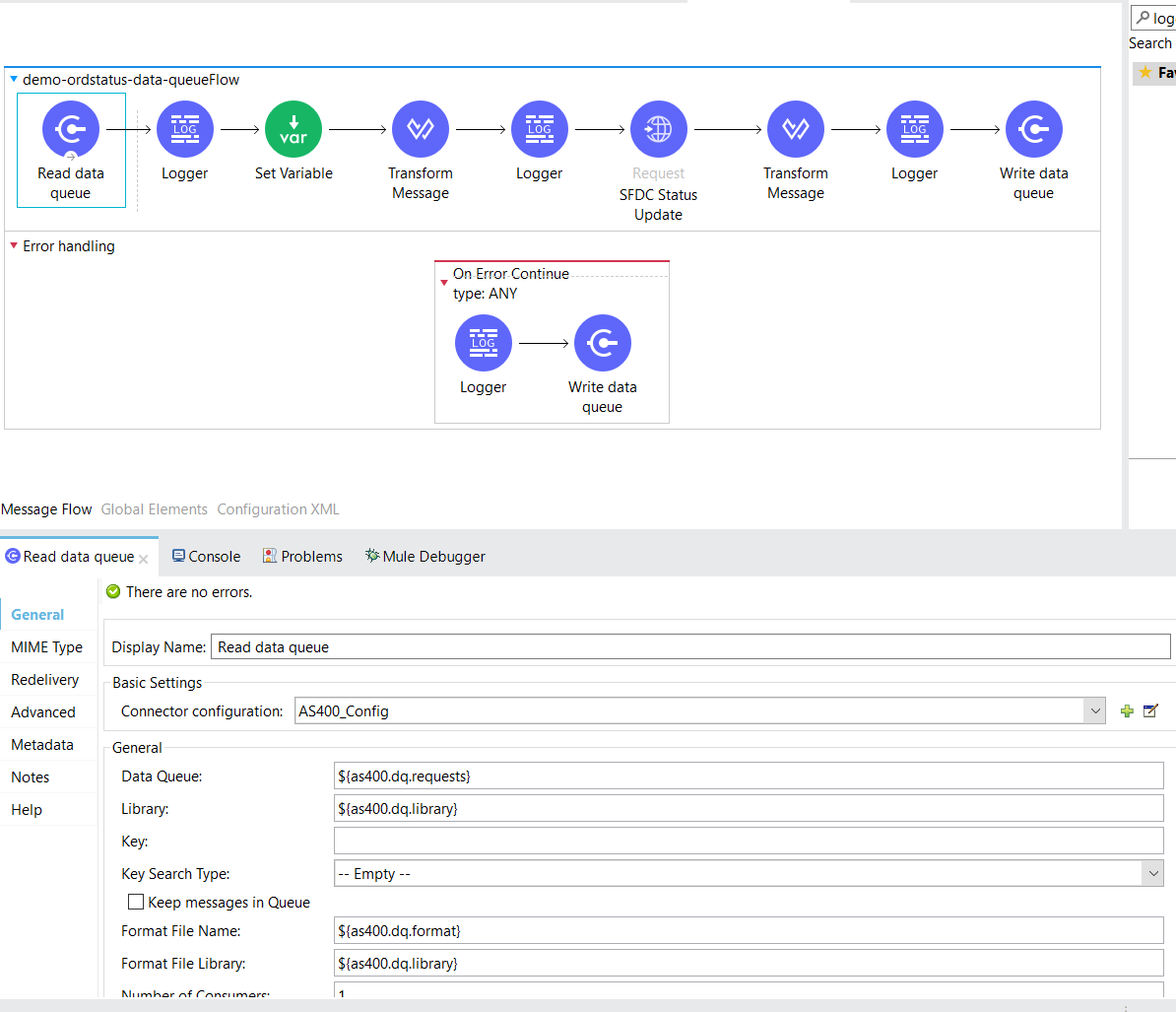
We specify the Data Queue name defined for the replication flow and provide a format file that gives the DQ message a structure and will be used for data type conversion. The rest of the listener flow stays pretty much the same as in the previously discussed example. We start our Mulesoft app and at this point, it’s ready to listen for data changes!
The last step in the process is to kick off our IBM i CDC Replication. We switch back to the terminal session and start the flow via infoCDC UI. At that point, any order status change is captured and sent to the Mulesoft app via the Data Queue, while any other changes or inserts or deletes are just ignored.
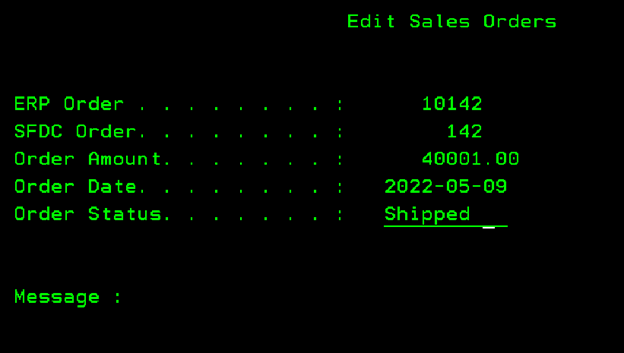
The moment we press Enter to save the new order status in our IBM i “ERP” (of course just a simple UI screen built on top of the simplified order header and detail tables), the infoCDC immediately grabs that change figures the change is needed based on the filtering rules and sends it to Mulesoft via the data queue. The Mulesoft connector receives and parses the message then posts it to Salesforce API to update the status there
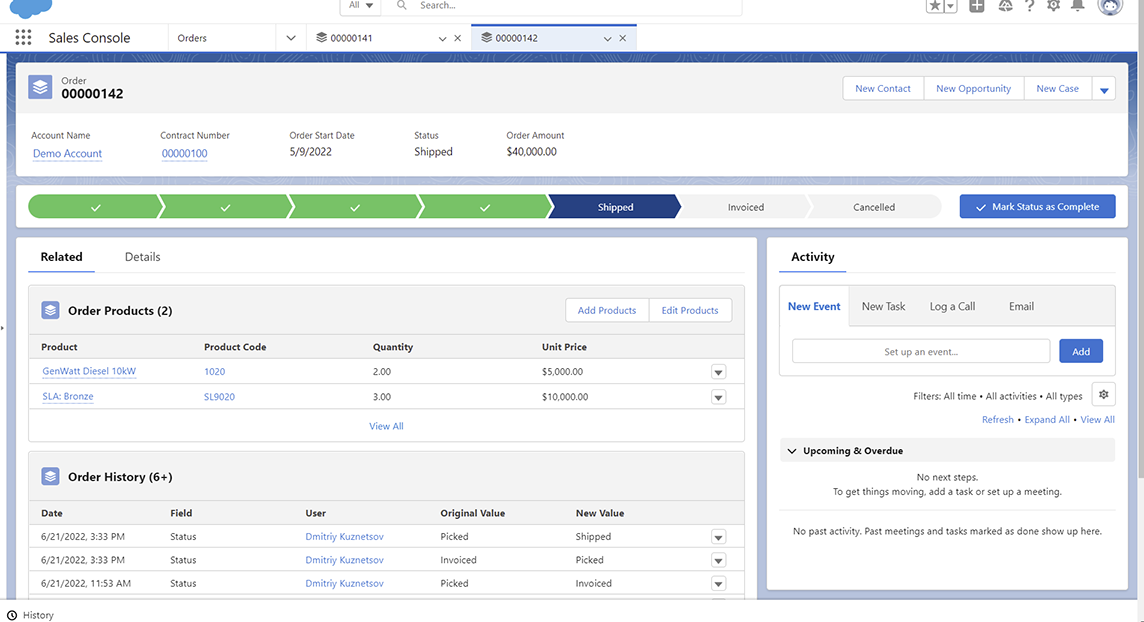
A quick check-in in Salesforce confirms that the update works as expected, and our order is now marked as Shipped!
Conclusion
Our upcoming infoCDC product, packaged with our infoConnect connectors for Mulesoft, Kafka, and upcoming AWS platforms, provides customers with a quick no-RPG-or-Cobol-Required way to detect and stream relevant changes from IBM i applications. There are various established Change Data Capture solutions focused on full data replication requirements. Most are focused on raw replication of the entire IBM i database, offer comprehensive snapshotting, auto-creating the target data models, and many other features. Naturally, it comes at a price. The majority of these solutions are rather complex, operate on their own infrastructure, and may offer limited options when it comes to data filtering and transformations. And of course, most of these solutions are pretty expensive. infoCDC fills the niche for customers looking for a lightweight, easy to operate, reasonably priced, zero IBM i coding CDC tool that plays nicely with Mulesoft and Kafka and focuses exclusively on database changes capture filtering and streaming.
Contact us to try infoCDC and learn more about the product features.
Recent Comments