
It is a common requirement to detect the data changes in core systems of record and apply them to other databases and applications in near real-time. Use cases range from simple (for example pushing ERP order status updates to CRM) to complex Kappa and Lambda data architectures focused on Big Data / AI / ML scenarios. In this article, we will show how to quickly implement a simple real-time data replication solution with Kafka Connect, Infoview’s infoConnect for Kafka connector, and our iInfoCDC change data capture product.
Use Case
Suppose we are a manufacturer and B2B focused distributor with our legacy ERP running on IBM i (formerly AS/400, iSeries) platform. The ERP works as expected and over time is adopted to our very specific business needs. The venerable IBM i – based infrastructure is built like a tank and securely supports the core process flows for our distributors. Now we want to expand our product reach and open a Direct to Consumer (D2C) channel. Brilliant move if we do it right and manage to not alienate our distributor and partner network, right? One often overlooked consideration is that D2C transaction volumes are typically orders of magnitude higher than the B2B levels our platforms and processes are currently optimized for. After rolling out our direct commerce channels, we quickly realized that the number of orders on an average day is hundreds or thousands of times higher. Among other things, the order status check is performed in several channel applications (mobile, web, partner marketplaces, etc.) and starts overwhelming our ERP / WMS system during peak load periods. Scaling up our IBM i infrastructure would be nice but it’s an expensive proposition, and still doesn’t protect us from spikes in demand such as during Black Friday.
The Solution
The problem is not new. One way to attack it is to maintain a near real-time replica of the most often used data, in this example order information. Then redirect the order status check API to use that replica instead of hitting our primary back-end ERP.
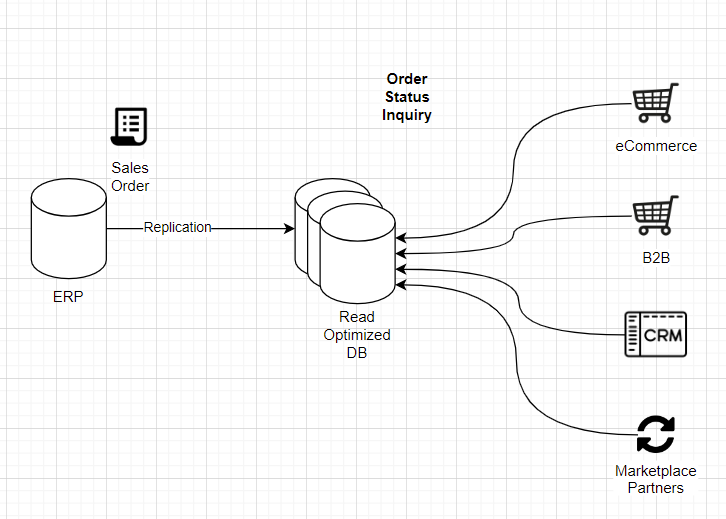
Sounds simple enough right? We can provide a scalable read-optimized cloud database such as AWS RDS or DynamoDB, stream ERP orders to that database, and repoint our D2C order status check queries and APIs to the new external database. This will take a big chunk off the transactions hitting our back-end ERP. Great, but how do we get the data from our IBM i based ERP to the external database in near real-time?
Several established vendors such as IBM and Informatica offer mature, powerful data replication solutions. They can replicate the entire schemas and databases, automatically detect structure changes, and have many more bells and whistles. On the other hand, they tend to be rather expensive and hard to implement and operate. Our infoCDC and Kafka Connect solution offers a lightweight, streamlined and economical product stack which is a good fit when the number of tables to replicate is not very high and there’s a benefit in filtering just relevant tables, columns and rows.
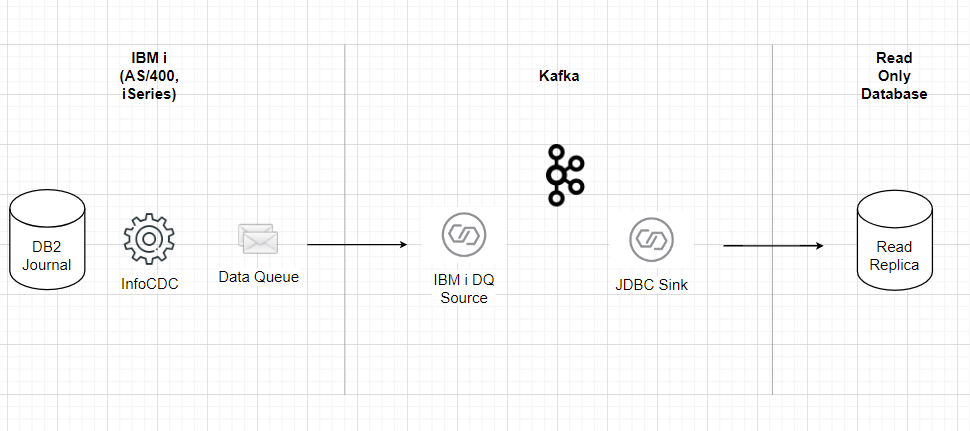
infoCDC Configuration
The IBM i CDC configuration is intuitive and simple. The product menu consists of two options – table maintenance and replication flow management:
First, we need to add a new table to the replication flow. We use option one, and on that screen key in new table and library and press F6 to add it.
The system will automatically load the table structure, and keys, validate if it’s properly journaled, and will prompt the user to select the filtering and replication rules:
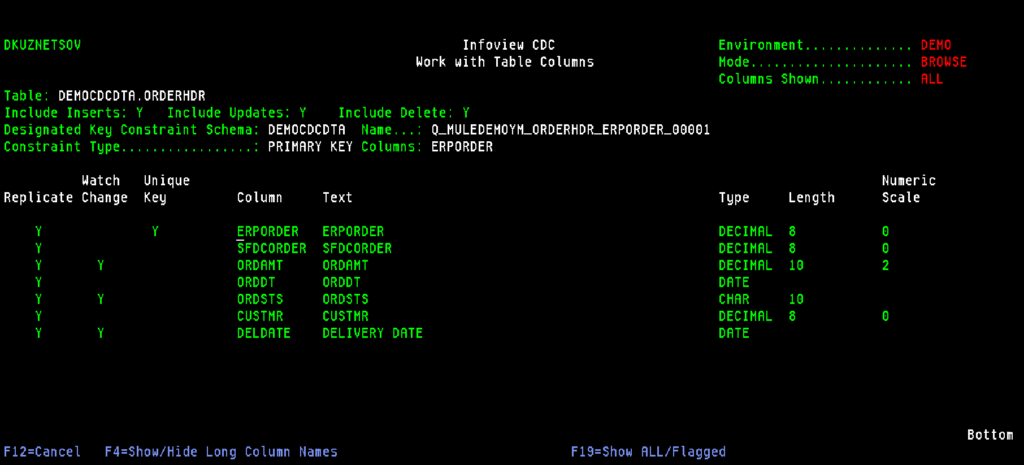
Here we can define the columns we want to watch the change for or send all the changes.
After the table is defined and saved, the product will auto-generate all required objects, including the replication data queue, replication message format table, etc.
In our case the order consists of the order header and details, therefore we will define both tables in the product.
Next, we need to start the replication flow for the associated journal in the second menu option.
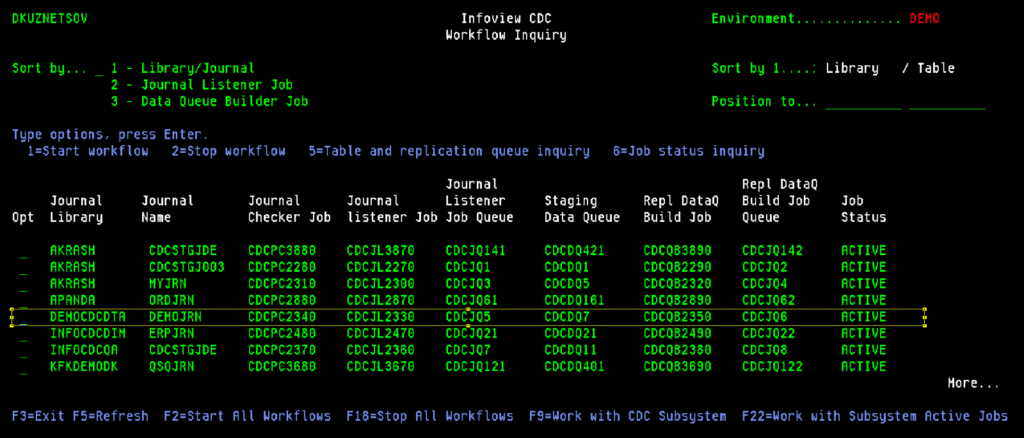
After the replication flow is active, we are ready to move on to Kafka configuration
Kafka Connect Configuration
We will use our Kafka Connect Data Queue Source connector, to listen for new messages, and JDBC Sink connector to upsert the data into our target MySQL table.
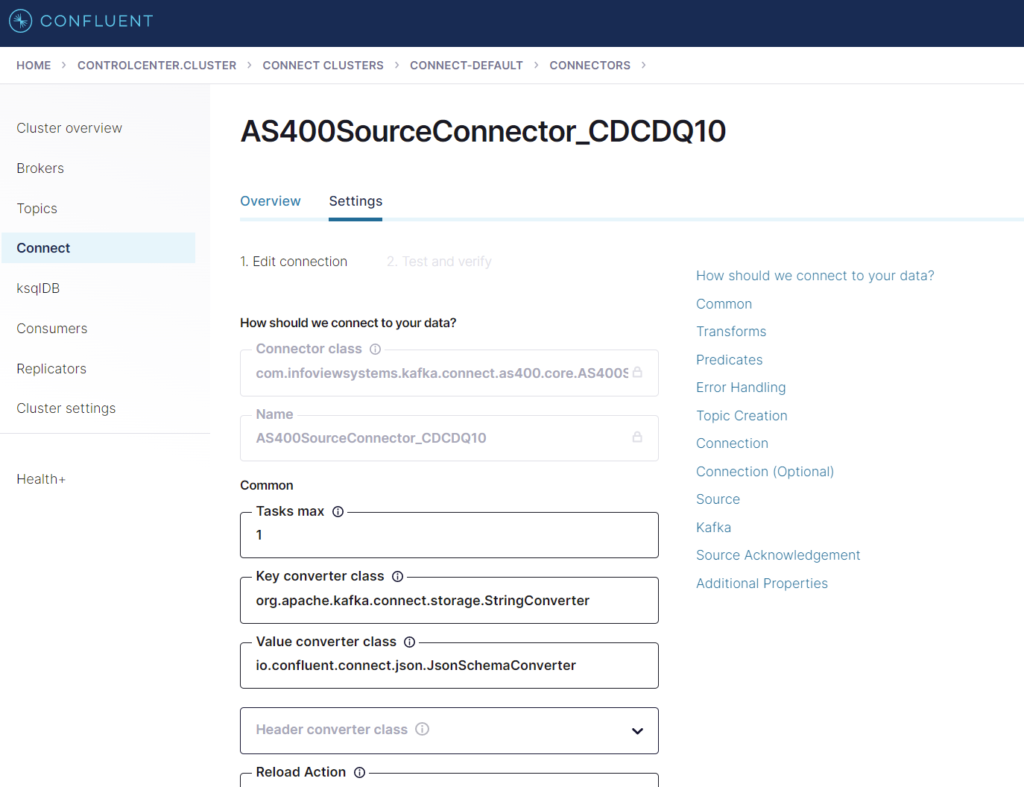
IBM i Data Queue Source Connector Configuration
Follow the configuration steps to visually configure the Data Queue listener.
On the connector, the screen provides the Data Queue name and Format File auto-generated by infoCDC for our order table, as well as IBM i connection information.
The connector will read a message from IBM i Data Queue, perform type translation per format table, transform it into JSON or AVRO format, and place the resulting message into Kafka topic.
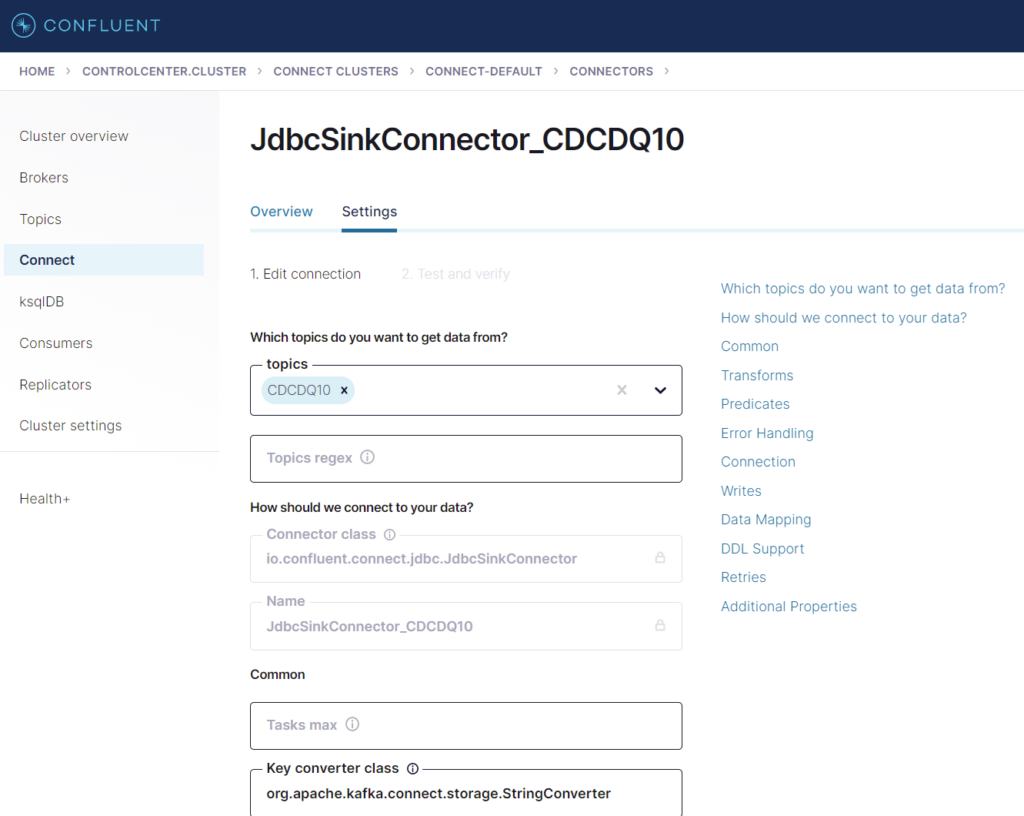
MySQL JDBC Sink Configuration
We will use a simple JDBC Sink connector that inserts or updates a record in the target MySQL table for each new message received from the Data Queue source on the same Kafka topic as we configured above.
We will need to provide the topic to listen for, the target DB connection details, the target table name, and a list of key columns to perform the upsert.
We will provide a similar configuration for Order Details, which will have its own Kafka topic, source, and target connector configurations.
After we start the Kafka cluster with related topics, connectors, and brokers, we are ready to test our replication solution.
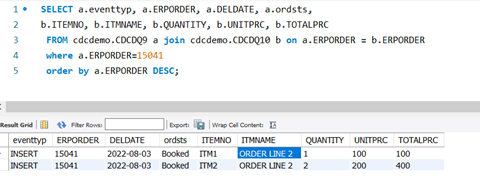
In our “ERP” we will create a new order
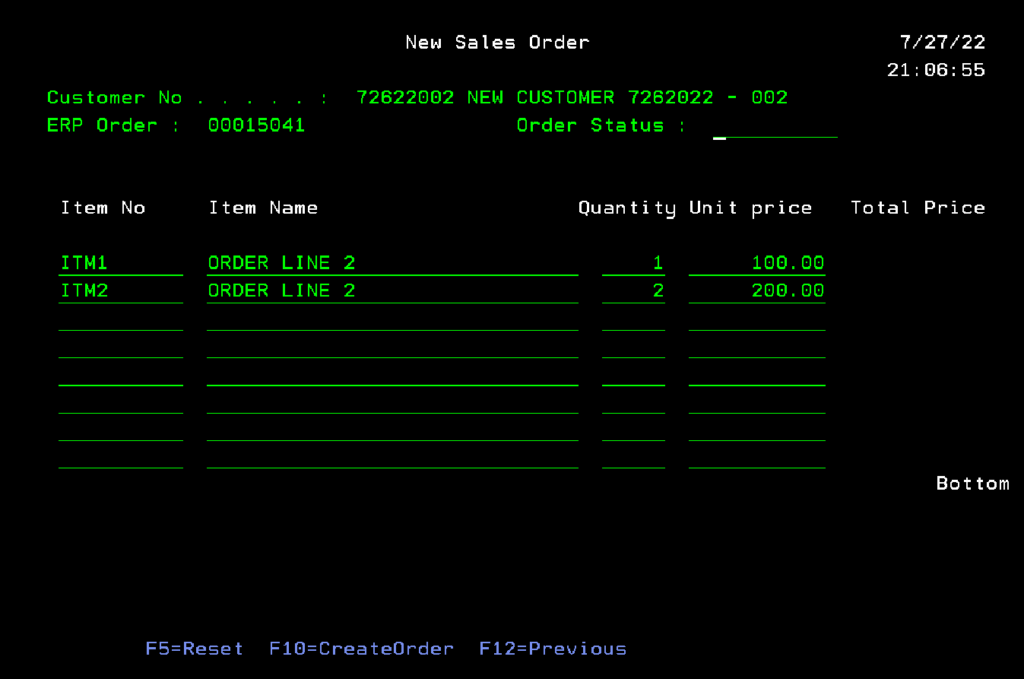
After immediately checking in the replication database, we can see the order made it there:
Conclusion
Our infoCDC product, combined with the Kafka platform, and infoConnect for Kafka connector, provides a simple no-code solution for replicating the data from IBM i to other databases in near real-time. The CDC product supports basic filtering, and column selection, and could be used for both application integration and data replication use cases. We did not have to write a single line of code for our admittedly simplified and controlled use case.
Contact us to request a trial license for infoCDC and Kafka Connectors, and learn more about our other products and services.
Recent Comments